
Introduction
Online coding assessments have become a cornerstone of remote technical hiring—but they've also opened the door to widespread fraud. Research analyzing 900,000 assessments found that 30% to 50% of candidates cheat during entry-level online job tests, with cheating rates doubling when no proctoring is in place.
Remote work now accounts for 22% of the U.S. workforce, and with 82% of developers experimenting with AI tools, candidates today have easy access to code generators, screen-sharing software, and solution databases.
This article breaks down the most common cheating methods, the real business cost of ignoring assessment integrity, and actionable prevention strategies that combine smart test design with technology-driven monitoring.
Key Takeaways
- Cheating methods have evolved beyond simple searches—candidates now use AI code generators, real-time collaborators, multiple devices, and solution databases
- Bad hires from undetected cheating cost organizations 30% of first-year salary, plus downstream team performance damage
- Effective prevention combines smart test design (multi-step problems, edge cases, unique variants) with detection tools like proctoring, code analysis, and behavioral monitoring
- No single tactic eliminates cheating entirely—combining test design and detection tools creates the strongest defense
- AI-powered proctoring platforms deliver consistent, objective integrity checks across high-volume hiring pipelines
How Candidates Cheat in Coding Assessments
Cheating in coding assessments has moved well past Googling answers. Candidates now use AI code generators, screen-sharing handoffs, and secondary devices in ways that standard webcam monitoring simply doesn't catch.
Using AI Tools Like ChatGPT and GitHub Copilot
Candidates copy-paste problem descriptions into AI tools to generate working code, then submit it as their own. A 2025 Virginia Tech study found ChatGPT achieved 72% accuracy on short LeetCode problems but dropped to just 31% on complex, narrative-driven Codeforces tasks.
The gap matters: AI performs best on simple, well-known problem structures. Unproctored take-home tests with generic prompts are particularly exposed — AI can produce near-perfect answers with no real candidate understanding required.
The risk is significant: 14% of candidates admit to using generative AI tools for assessments, while 83% say they would use AI assistance if they thought employers wouldn't detect it.

Enlisting External Help via Screen Sharing
Candidates use screen-sharing apps like Zoom or TeamViewer to let a third party watch and guide them in real time — or hand over full device control entirely. This tactic thrives in asynchronous, unsupervised assessments where no identity verification is in place.
Tech-savvy candidates go further, using semi-transparent overlays that don't appear in screen recordings. Detection requires behavioral monitoring — standard webcam checks won't catch it.
Using Multiple Devices to Look Up Answers
Candidates keep a phone, tablet, or second laptop out of their webcam's field of view to search for solutions on GitHub, Stack Overflow, or coding forums while their primary screen is being monitored. Without device proximity detection or strict environmental checks, this approach is nearly invisible to assessors.
Copying Known Solutions from the Internet
When assessments rely on generic or publicly documented challenges, candidates can source exact solutions and rewrite them line by line to sidestep copy-paste detection. Static question banks are especially vulnerable. Candidates often research:
- The specific challenge title or problem type before the test starts
- GitHub repositories with accepted solutions for known LeetCode or HackerRank problems
- Dedicated cheat forums that catalog common assessment questions by company
What Happens If Cheating Goes Unchecked
The most direct consequence is bad hires. A candidate who cannot actually code will fail on the job. The U.S. Department of Labor estimates a bad hire costs approximately 30% of the individual's first-year earnings, while SHRM reports replacement costs ranging from 90% to 200% of annual salary for specialized roles.
Beyond the financial hit, downstream effects compound the damage:
- Team performance drag - Engineering teams inherit underqualified colleagues who slow projects and require constant support
- Morale issues - Top performers become frustrated carrying unqualified teammates
- Recruiter credibility damage - Hiring managers lose trust in assessment processes
- Time-to-rehire costs - Organizations must restart the entire hiring cycle, extending vacancies and productivity gaps
A CareerBuilder survey found companies lost an average of $14,900 on every bad hire, citing less productivity (36%), compromised work quality (33%), and negative impact on employee morale (31%) as primary impacts.

Warning Signs You're Dealing with Assessment Cheating
Those costs make early detection critical. Catching cheating starts with recognizing behavioral patterns during and after the assessment.
Submission time vs. expected duration: A candidate who completes a complex multi-step problem in a fraction of the typical window may have had outside help. Speed alone isn't suspicious, but unusually short completion times deserve a closer look, especially alongside other signals.
Score and interview don't match: A candidate who aced the coding test but can't walk through their own solution is a strong signal the work wasn't theirs. Watch for:
- Long pauses when asked follow-up questions
- Inability to explain logic or edge cases
- Verbal fluency that doesn't match technical depth
Code that doesn't feel earned: AI-generated or copied code often carries tell-tale signs — high similarity scores, no incremental edits or commits, and patterns that don't match the candidate's stated experience level. Instant large-block pastes with no intermediate typing activity are among the clearest red flags.
How to Build Cheat-Resistant Coding Assessments
Smart test design reduces cheating opportunities before any monitoring tool needs to kick in. This proactive layer of defense makes assessments inherently harder to game.
Design Multi-Step, Complex Problems
AI tools and online solutions perform well on simple, single-step problems but degrade as complexity and the number of interdependent logic steps increase. The Virginia Tech study demonstrated this clearly: ChatGPT's accuracy plummeted from 72% to 31% when problems required multi-step reasoning and narrative context.
When to implement: Use multi-step problems as the standard for mid-to-senior level roles where genuine problem-solving ability is the core hiring criterion. Structure challenges that require candidates to:
- Parse and integrate information from multiple sources
- Handle interdependent logic across several functions
- Maintain context across multiple files or modules
- Reason through cascading consequences of design decisions
Incorporate Edge Cases and Special Conditions
Edge cases—scenarios outside the typical "happy path"—require contextual understanding and creative thinking that AI tools and online solutions routinely miss. Candidates relying on AI or copied code will fail edge case test cases, exposing the gap between their submission and real understanding.
Design problems that include boundary conditions, null handling, performance constraints under extreme inputs, or unusual data formats. This forces candidates to show they actually understand the problem — not just recognize its shape.
Use Unique, Personalized Problem Variants
Coderbyte uses an "output modification" approach that appends a candidate-specific requirement to standard problems. By incorporating the candidate's unique ID into a second step requiring 4-7 additional lines of code, the solution becomes 100% unique and impossible to find online—without adding meaningful difficulty for honest candidates.
When to implement: Apply to any assessment where the challenge pool is known or could be researched—particularly for high-volume screening where the same problems are sent to many candidates.
Avoid Generic, Well-Known Problem Structures
Build or source proprietary problems that mirror real-world scenarios at your company rather than standard LeetCode-style problems with published solutions. Think system-specific edge cases, business-domain logic, or context-specific data that can't be Googled.
This approach also strengthens prediction of on-the-job performance:
- Tests how candidates solve problems in your specific environment
- Reveals domain reasoning, not just memorized CS patterns
- Reduces the value of generic prep resources entirely
Using Technology to Detect and Prevent Cheating
While smart test design reduces cheating opportunity, proctoring and detection technology catches what slips through by monitoring candidate behavior, not just output.
AI-Powered Proctoring and Behavioral Monitoring
Modern proctoring tools use webcam monitoring, audio analysis, and periodic snapshots to flag suspicious environmental conditions—such as a second person in the room, a candidate looking away from the screen, or the presence of unauthorized devices.
AltHire AI takes this further by embedding proctoring directly into a conversational interview flow rather than a static test window. Behavior is monitored continuously across multiple signals:
- Visual integrity - Real-time face comparison, multiple face detection, and suspicious eye movement tracking
- Audio monitoring - Detection of multiple voices, background noise, and AI-produced speech
- Environmental checks - Mobile phone detection, unauthorized device flagging, and lighting verification
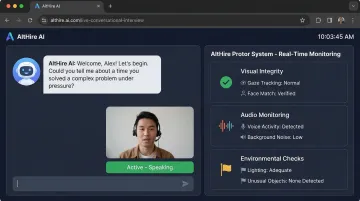
This makes cheating significantly harder to conceal while keeping the experience less intrusive than static test environments.
Tab-Switch Detection and Browser Lockdown
Locked browsers or smart browser modes restrict candidates from switching tabs, opening new windows, or accessing external applications during the assessment. Tab-switch counts are logged and flagged for reviewer attention, with platforms like HackerRank and Codility tracking the duration and frequency of focus changes.
Code Similarity and Plagiarism Analysis
Platforms compare submitted code against known AI-generated baselines, online solution databases, and previous candidate submissions to calculate similarity scores. HackerRank reports its dual-model architecture achieves 93% accuracy in detecting AI-generated code. Paraphrased or reformatted AI code still produces higher similarity scores than human-written code, due to structural patterns and recurring AI-generated idioms.
Typing Pattern and Behavioral Analysis
Tools detect unnatural coding behavior: large blocks of code appearing instantly (indicating a paste), no incremental edit history, or typing patterns that don't match the time elapsed.
Platforms like TestGorilla and CoderPad note that these automated flags are symptoms requiring review, not outright proof. Hiring teams should examine code playback timelines for bursts of activity that don't align with normal typing pace.
Long-Term Practices for Assessment Integrity
No single assessment setup holds up forever. Sustaining a cheat-resistant process means building habits that evolve with candidate behavior and grow smarter over time:
- Rotate and refresh your question bank regularly - Retire problems that have circulated online and introduce new proprietary challenges on a regular cadence to stay ahead of shared answer pools
- Follow every assessment with a live code review - Walking candidates through their own solution confirms genuine understanding and discourages cheating when candidates know a debrief is expected
- Document behavioral flags for every flagged submission - Log unusually fast completion times, high similarity scores, and interview-vs-assessment inconsistencies in a shared record. This builds team-wide awareness and sharpens your assessment design over time.
Frequently Asked Questions
How do coding assessment platforms detect and prevent cheating?
Platforms use a combination of AI proctoring (webcam, audio, snapshots), tab-switch detection, browser lockdown, code similarity analysis, and typing pattern monitoring. The most effective approach layers smart test design with these detection tools rather than relying on any single mechanism.
Can AI-generated code be detected in coding assessments?
AI-generated code often shows clear indicators: instant large-volume pastes, higher similarity scores against known AI baselines, no incremental edit history, and solutions that fail edge cases. Behavioral analysis tools are specifically built to flag these patterns with high accuracy.
Does adding proctoring negatively impact candidate experience?
Overly invasive proctoring can feel intimidating, but modern AI proctoring integrated into a conversational interview flow is far less disruptive than surveillance-heavy static tests. Transparent communication about monitoring upfront sets the right expectations and maintains candidate trust.
What types of coding problems are most difficult to cheat on?
Multi-step problems with interdependent logic, heavy edge case requirements, unique personalized output modifications, and context-specific real-world scenarios are the hardest to solve using AI tools or online solutions. These problems require genuine understanding rather than pattern matching.
How should recruiters follow up if they suspect a candidate cheated?
Conduct a structured technical debrief where the candidate explains their solution approach, walks through their code logic, and handles a minor variation of the same problem live. Genuine understanding will be apparent immediately through their ability to reason about design decisions and adapt to new requirements.
Is it possible to make a coding assessment completely cheat-proof?
No assessment is 100% cheat-proof, but combining smart test design, personalized problem variants, AI proctoring, and a follow-up technical conversation creates a system where cheating becomes too difficult and risky to attempt effectively. When the effort to cheat exceeds the effort to prepare, most candidates will simply prepare.


