
Introduction
Recruiters today face a growing challenge: coding assessments have become standard in technical hiring, but so has plagiarism. From candidates copying solutions directly from GitHub to AI-generated submissions that look nearly identical to original work, cheating methods have outpaced most hiring teams' ability to catch them — leaving assessments that can't reliably measure what candidates actually know.
The stakes are high. According to the U.S. Department of Labor, the cost of a bad hire can reach 30% of the employee's first-year earnings, while SHRM estimates the total organizational cost at up to $240,000 for specialized technical roles. When undetected plagiarism allows unqualified candidates to pass screening, these costs become inevitable.
To avoid that outcome, this article walks through what plagiarism detection in coding assessments actually means, the three core methods used to catch it, and how to choose the right approach for your hiring context without sacrificing candidate experience or accuracy.
Key Takeaways
- Plagiarism in coding assessments spans repository copying, candidate collusion, and AI-generated submissions
- Detection methods fall into three categories: code similarity analysis, behavioral monitoring, and proctored identity verification
- Combining automated detection with human review consistently outperforms any single-method approach
- The right method depends on your assessment format, hiring volume, and the cheating methods you're most likely to encounter
- Automated flags guide decisions — they should never replace human judgment
What Is Plagiarism Detection in Coding Assessments?
Plagiarism detection in coding assessments is the process of using automated tools and human review to identify code submissions that are unusually similar to known sources or that show behavioral indicators of dishonesty. It targets three distinct forms of code plagiarism that compromise hiring integrity.
The three main forms:
- Copying from external sources - Candidates lift solutions from public repositories like GitHub, Stack Overflow, or leaked assessment banks
- Candidate-to-candidate collusion - Multiple candidates taking the same test share answers or coordinate responses in real time
- AI tool misuse - Candidates use tools like ChatGPT or GitHub Copilot to generate solutions when explicitly prohibited
Plagiarism detection functions as a practical safeguard within the hiring workflow. It collects behavioral and code-level signals, then produces flagged reports for hiring teams to act on. The goal is to surface dishonesty early, before unqualified candidates advance to costly interview rounds or receive offers based on fabricated skills.
Modern detection systems analyze both the final code artifact (what was submitted) and the behavioral signals during the assessment (how it was written). This dual approach addresses the reality that candidates who copy often modify code enough to fool simple text comparison — so modern tools go further, using abstract syntax tree (AST) analysis, keystroke timing, and tab-switch detection to catch evasion attempts.
Why Does Plagiarism in Coding Assessments Matter for Hiring?
Undetected plagiarism doesn't just compromise one assessment—it cascades into real organizational costs. A candidate who passes a compromised coding test lacks the verified skills the role requires, increasing the risk of early attrition, underperformance, and wasted onboarding investment.
CodeSignal reported that fraud attempt rates more than doubled year-over-year, rising from 16% in 2024 to 35% in 2025. Entry-level hiring is particularly vulnerable, with fraud attempts jumping from 15% to 40% in the same period. During fall campus recruiting seasons, up to 25% of technical assessments show signs of plagiarism.
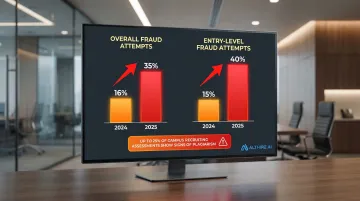
What goes wrong without structured detection:
Standard resume reviews and manual code evaluation alone cannot reliably identify plagiarism at scale. When candidates use AI tools or make minor modifications to copied code—renaming variables, reordering functions, adding comments—the plagiarism appears original at a glance. Even experienced technical reviewers struggle to spot these patterns without automated support, especially when reviewing dozens or hundreds of submissions.
Detection also serves a deterrent function. When candidates know monitoring is active, attempted plagiarism drops. Research shows that admitted cheating rates fell from 5.4% in unproctored environments to 2.8% when passive proctoring with live check-in was used—demonstrating that visible accountability improves the integrity of the entire candidate pool.
Methods of Plagiarism Detection in Coding Assessments
Plagiarism detection is not one-size-fits-all. Different methods target different cheating behaviors and work best in different assessment contexts. Understanding how each method operates—and where it falls short—helps you build a detection strategy that matches your hiring needs.
Code Similarity-Based Detection
This method compares the structural and syntactic composition of a submitted code solution against a database of past submissions, public repositories, and known leaked solutions. Tools like MOSS (Measure of Software Similarity) use token-based and Abstract Syntax Tree (AST) analysis to detect matches beyond surface-level text comparison.
The system accounts for variable renaming, reformatting, and code reordering by tokenizing source code to strip superficial features like whitespace and comments, then applying a "winnowing" algorithm for document fingerprinting.
Unlike behavioral or proctoring methods, this approach focuses entirely on the static artifact — what was submitted — rather than how it was written or who wrote it. It requires no monitoring during the test, making it the lowest-friction option for candidates.
It works best for:
- Detecting direct copying between candidates taking the same test
- Catching submissions sourced from public forums or repositories
- High-volume screening where many submissions need rapid comparison
- Serving as the default baseline detection layer on most technical assessment platforms
Limitations:
False positives appear when candidates independently reach similar solutions, when common libraries are included, or when code is too short for meaningful comparison. Research shows ChatGPT-produced solutions had measurably lower pairwise similarity to other submissions than human solutions, allowing AI-generated code to slip through MOSS undetected. The tool's creators explicitly warn that relying solely on similarity scores is a "misuse" — human review remains mandatory.
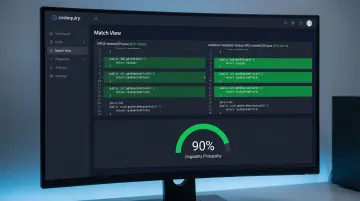
AI/ML-Powered Behavioral Detection
This method uses machine learning models to analyze behavioral signals captured during the assessment to identify suspicious patterns indicating the code was not independently written. Monitored signals include keystroke patterns, copy-paste activity, time taken per problem, tab-switching frequency, and code iteration history.
Unlike code similarity detection, this approach focuses on how the code was produced rather than what was submitted. It can identify AI-generated submissions even when the code has no match in any database, because the behavioral fingerprint of typing out AI-suggested code differs from genuine problem-solving.
It works best for:
- Detecting AI tool misuse when structural comparison alone fails
- Identifying candidates who paste large sections of pre-written code
- Catching sophisticated cheaters who modify copied code enough to evade similarity checks
- Addressing the growing challenge of generative AI in technical hiring
AltHire AI's advanced AI proctoring layer uses this type of behavioral analysis, monitoring signals in real time and flagging attempts for recruiter review. The system tracks copy-paste activity, keyboard shortcuts, tab-switching frequency, unusual coding speed, and coding pattern inconsistencies throughout the assessment.
Limitations:
ML models require sufficient behavioral data to generate reliable predictions. Short problems with few lines of code may not produce enough signals for accurate classification. HackerRank notes that AI plagiarism detection is limited when evaluating questions requiring minimal effort, as these scenarios lack the data points ML needs. Human review remains essential: 85% precision means 15% of flags may be false positives requiring contextual judgment.
Proctoring and Identity Verification-Based Detection
This method focuses on the candidate environment and identity rather than the code itself. It encompasses webcam monitoring, browser lockdown, screen activity recording, network IP detection, and photo ID verification with facial recognition — confirming the right person is taking the test under supervised conditions.
This approach addresses impersonation and external assistance — concerns that neither code similarity analysis nor behavioral ML detection can fully address. Even if the code looks original and the typing patterns seem natural, proctoring verifies whether the person taking the test is actually the candidate.
It works best for:
- High-stakes technical hiring where identity fraud is a concern
- Remote take-home assessments where no environmental controls exist
- Organizations requiring documented audit trails for compliance purposes
- Deterring organized "proxy interviewing" services where professionals take tests on behalf of candidates
The FBI issued warnings in 2022 regarding an increase in candidates using deepfakes and lip-syncing during remote video interviews. Gartner predicts that by 2028, one in four candidate profiles worldwide will be fake, driven by AI and identity manipulation.
Key strengths:
- Deters impersonation outright and creates a visible accountability layer that reduces attempted cheating
- Generates video and behavioral logs reviewable alongside code similarity and behavioral detection reports, providing comprehensive evidence when integrity issues arise
Limitations:
Proctoring is more invasive than other methods and requires explicit candidate consent before the assessment begins. Full proctoring can affect candidate experience, particularly in regions where privacy norms differ. Under GDPR, biometric data used for unique identification is classified as "special category data", requiring careful legal compliance.
Network IP detection can also generate false positives when candidates legitimately switch from Wi-Fi to mobile data mid-assessment. Codility explicitly warns that IP change flags are not guarantees of cheating.
How to Choose the Right Detection Method
The choice depends on the specific cheating risk your assessment is most vulnerable to, not on what is most technologically sophisticated or commonly used by competitors.
Key factors to weigh:
- Assessment format — In-platform assessments allow real-time behavioral monitoring; take-home assessments rely more on code similarity detection and cross-candidate pattern analysis.
- Problem complexity — Short or simple problems generate fewer behavioral signals. For assessments with minimal code requirements, similarity-based detection tends to be more reliable.
- Scale — High-volume screening benefits most from automated similarity detection that can process hundreds of submissions without manual review bottlenecks.
- Cheating sophistication — AI-generated submissions require ML behavioral detection, not just similarity checks. If your candidate pool uses advanced AI tools, behavioral monitoring becomes essential.
- Budget and tooling — Not every team needs full proctoring. Match your detection layers to the actual risk level of each hiring stage.
Recommended layered approach for most hiring contexts:
| Hiring Stage | Detection Layers | Rationale |
|---|---|---|
| High-volume screening | Code similarity + basic behavioral telemetry (tab-tracking, copy-paste) | Rapid automated processing with minimal false positives |
| Mid-level technical screening | ML behavioral detection + webcam snapshots | Catches AI-generated code and sophisticated copying |
| Senior/high-stakes finals | Full proctoring + identity verification + live code review | Strongest verification for high-stakes decisions |

Platforms that combine these layers into a single workflow — like AltHire AI — remove the burden of selecting and stitching together separate tools. Recruiters get a unified view of behavioral signals, code patterns, and candidate identity in one report.
Critical principle: Regardless of which methods are enabled, human review of flagged cases must be part of the workflow. Automated flags should trigger review, not automatic rejection — no system should disqualify a candidate without a human making the final call.
Common Mistakes to Avoid When Implementing Plagiarism Detection
Treating automated flags as final verdicts
Similarity scores and behavioral flags are decision-support signals — not evidence of guilt. False positives are a real risk: candidates using common templates, solving simple problems, or switching networks mid-test can all trigger incorrect flags.
Vendors like TestGorilla note that anti-cheating monitors highlight "symptoms of behavior, not outright proof of cheating" and explicitly advise against immediate disqualification based on flags alone.
Relying on a single detection method
Every method has blind spots:
- Code similarity misses AI-generated submissions
- Behavioral detection lacks enough data on short problems
- Proctoring alone cannot verify code originality
Organizations that depend on one layer leave exploitable gaps. Combining AI analysis, behavioral signals, and visual monitoring catches evasion tactics that any single method would miss.
Skipping pre-assessment disclosure
Candidates should know upfront that plagiarism detection is active and which behaviors are flagged. This serves both a deterrent purpose and a legal one — under GDPR and emerging AI regulations, candidates must be informed of automated processing logic and must consent to biometric data collection.
Clear disclosure reduces disputes, sets expectations before the test begins, and demonstrably lowers cheating attempts.
Conclusion
Plagiarism detection in coding assessments works across multiple layers. It combines code similarity analysis, AI/ML behavioral monitoring, and proctoring with identity verification, each addressing different forms of cheating that threaten hiring integrity.
The goal of detection is not to punish candidates but to ensure the assessment accurately reflects genuine ability. This benefits both the employer making a hiring decision and the candidate being evaluated fairly. With fraud attempt rates more than doubling year-over-year and AI tools making cheating easier than ever, skipping structured detection is no longer a defensible choice for any serious hiring process.
Choose your detection layers based on your specific hiring context, implement them transparently, and always pair automated flags with human review. When those elements work together, you get a process that's harder to game and fairer for candidates who aren't trying to.
Frequently Asked Questions
Can plagiarism detection in coding assessments produce false positives?
Yes, false positives can occur. Common causes include similar solutions to simple problems, shared starter templates, or network changes triggering IP flags. Human review of flagged cases catches these scenarios before any action is taken against a candidate.
How do plagiarism detection tools handle AI-generated code from tools like ChatGPT?
Traditional code similarity tools often cannot detect AI-generated code because it may be structurally unique. AI/ML-powered behavioral detection addresses this gap by analyzing how the code was written, identifying copy-paste bursts, atypical timing, and coding pattern anomalies characteristic of AI-assisted submissions.
Is code similarity between two candidates always evidence of plagiarism?
Not necessarily. High similarity can occur when candidates independently solve a simple problem the same way, or when shared libraries inflate the match score. Reviewers should examine flagged segments, problem complexity, and submission metadata before drawing conclusions.
What behavioral signals do AI-powered detection tools typically monitor?
Key signals include copy-paste activity, tab-switching frequency, unusual keystroke patterns, and code iteration history (for example, going from zero to a complete solution in implausibly short time). The ML model aggregates these signals into a confidence-scored flag.
Do candidates need to be told that plagiarism detection is active during their coding assessment?
Transparency is both a legal and ethical requirement in most contexts, particularly for behavioral ML detection and proctoring, which typically require explicit candidate consent before the assessment begins. Clear disclosure also serves as a deterrent, reducing attempted cheating.
Does plagiarism detection work for take-home coding assessments?
Code similarity detection and cross-candidate pattern analysis work well for take-home assessments, while behavioral monitoring and proctoring are more limited without a controlled environment. Combining randomized question banks, time-limited windows, and post-submission similarity checks is the most practical approach for unsupervised take-home tests.


